 This is a guest post by Jesse Storimer. He teaches the Unix fu workshop, an online class for Ruby developers looking to do some awesome systems hacking in Ruby and boost their confidence when it comes to their server stack. Spots are limited, so check it out the class while there's still room. He's also the esteemed author of Working with Unix Processes, Working with TCP Sockets and Working with Ruby Threads.
This is a guest post by Jesse Storimer. He teaches the Unix fu workshop, an online class for Ruby developers looking to do some awesome systems hacking in Ruby and boost their confidence when it comes to their server stack. Spots are limited, so check it out the class while there's still room. He's also the esteemed author of Working with Unix Processes, Working with TCP Sockets and Working with Ruby Threads.
There are some misconceptions in the Ruby community about this question surrounding MRI's GIL. If you only take one thing away from this article today, let it be this: The GIL does not make your Ruby code thread-safe.
But you shouldn't take my word for it.
This series started off just trying to understand what the GIL is at a technical level. Part 1 explained how race conditions could occur in the C code that's used to implement MRI. Yet, the GIL seemed to eliminate that risk, at least for the Array#<< method we looked at.
Part 2 confirmed that the GIL did, in fact, make MRI's native C method implementations atomic. In other words, these native implementations were free from race conditions. These guarantees only applied to MRI's native C functions, not to the Ruby that your write. So we were left with a lingering question:
Does the GIL provide any guarantee that your Ruby code will be thread-safe?
I've already answered that question. Now I want to make sure that the misconception doesn't go any further.
Race conditions redux
Race conditions exist when some piece of data is shared between multiple threads, and those threads attempt to act on that data at the same time. When this happens without some kind of synchronization, like locking, your program can start to do unexpected things and data can be lost.
Let's step back and recap how such a race condition can occur. We'll use the following Ruby code example for this section:
class Sheep
def initialize
@shorn = false
end
def shorn?
@shorn
end
def shear!
puts "shearing..."
@shorn = true
end
endThis class definition should be nothing new. A Sheep is not shorn when initialized. The shear! method performs the shearing and marks the sheep as shorn.

sheep = Sheep.new
5.times.map do
Thread.new do
unless sheep.shorn?
sheep.shear!
end
end
end.each(&:join)The bit of code creates a new sheep and spawns 5 threads. Each thread races to check if the sheep has been shorn? If not, it invokes the shear! method.
Here's the result I see from running this on MRI 2.0 several times.
$ ruby check_then_set.rb
shearing...
$ ruby check_then_set.rb
shearing...
shearing...
$ ruby check_then_set.rb
shearing...
shearing...Sometimes the same sheep is being shorn twice!
If you were under the impression that the GIL made your code 'just work' in the presence of multiple threads, this should dispel that. The GIL can make no such guarantee. Notice that the first time running the file, the expected result was produced. In subsequent runs, unexpected output was produced. If you continued running the example, you'll see still different variations.
These unexpected results are due to a race condition in your Ruby code. It's actually a common enough race condition that there's a name to describe this pattern: a check-then-set race condition. In a check-then-set race condition, two or more threads check a value, then set some state based on that value. With nothing to provide atomicity, it's possible that two threads race past the 'check' phase, then both perform the 'set' phase.
Recognizing race conditions
Before we look at how to fix this, first I want you to understand how to recognize this. I owe @brixen for introducing to me the terminology of interleavings in the context of concurrency. It's really helpful.
Remember that a context switch can occur on any line of your code. When switching from one thread to another, imagine your program being chopped up into a set of discrete blocks. This sequential set of blocks is a set of interleavings.
At one end of the spectrum, it's possible that there's a context switch after every line of code! This set of interleavings would have each line of code interleaved. At the other end of the spectrum, it's possible that there are no context switches during the body of the thread. This set of interleavings would have all the code in its original order for each thread. In between these two ends, there are lots of ways that your program can be chopped up and interleaved.
Some of these interleavings are OK. Not every line of code introduces a race condition. But imagining your programs as a set of possible interleavings can help you recognize when race conditions do occur. I'll use a series of diagrams to show this code may be interleaved by two Ruby threads.

Just to make the diagrams simpler, I replaced the shear! method call with the code from the body of the method.
Consider this diagram the legend for the ones to follow; the code highlighted in red is the set of interleavings from Thread A, the code highlighted in blue is the set of interleavings from Thread B.
Now let's see how this code could be interleaved by simulating context switches. The simplest case is if neither thread is interrupted during the course of executing this code. This would result in no race conditions and would produce the expected output for us. That might look like this:

Now I've organized the diagram so you can see the sequential ordering of events. Remember that the GIL locks around the execution of Ruby code, so two threads can't truly run in parallel. The ordering of events here is sequential, starting at the top and working down.
In this interleaving, Thread A did all of its work, then the thread scheduler triggered a context switch to Thread B. Since Thread A had already done the shearing and updated the shorn variable, Thread B didn't have anything to do.
But it isn't always this simple. Remember that the thread scheduler could trigger a context switch at any point in this block of code. This time we just got lucky.
Let's look at a more nefarious example, one that would produce unexpected output for us.
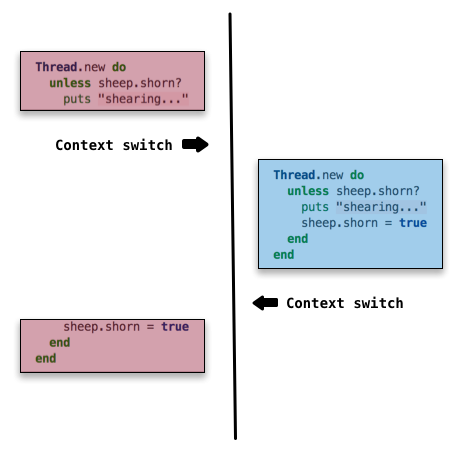
In this possible interleaving, the context switch occurs right at a point that can cause trouble. Thread A checks the condition and starts shearing. Then the thread scheduler schedules a context switch and Thread B takes over. Even though Thread A already performed the shearing, it didn't get a chance to update the shorn attribute yet, so Thread B doesn't know about it.
Thread B checks the condition for itself, finds it to be false, and shears the sheep again. Once it finishes, Thread A is scheduled again and finishes execution. Even though Thread B set shorn = true when it ran through the code, Thread A does it again because it picks up exactly where it left off.
A sheep getting shorn twice may not seem like much to care about, but replace sheep with invoice, and shearing with collecting payment; we would have some unhappy customers!
I'll share one more example to illustrate the non-deterministic nature of things here.
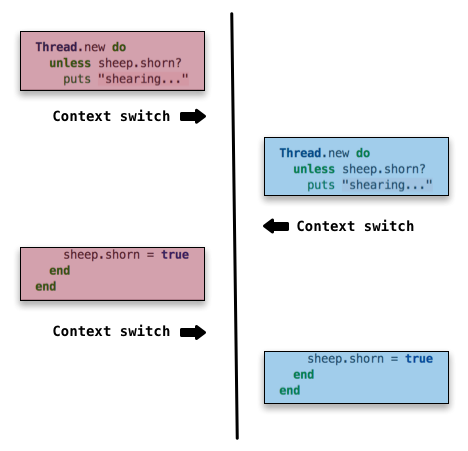
This just adds more context switches, so each thread progresses a little bit at a time, but keeps switching back and forth. Let your mind take this to its logical conclusion, it's possible for a context switch to happen on any line of the program. The interleaving that occurs can also be different each time the code is executed, so it may produce the expected result on one iteration, and an unexpected result the next time around.
This is really a great way to think about race conditions. When you're writing multi-threaded code, you want to be thinking about how the program might be chopped up and interleaved, and the effects of various interleavings. If it seems that some interleavings will lead to incorrect results, you should re-think your approach to the problem or introduce synchronization with Mutex.
This is terrible!
At this point it seems fitting to tell you that you can make this code example thread-safe by introducing synchronization with Mutex. It's true, you can do that. But I intentionally cooked up this example to prove a point; it's terrible code. You shouldn't write code like this in a multi-threaded environment.
Whenever you have multiple threads sharing a reference to an object, and making modifications to it, you're going to run into trouble unless you have some kind of locking in place to prevent a context switch from happening in the middle of the modification.
However, this particular race condition is easily solvable without explicitly using locks in your code. Here's one solution using Queue:
require 'thread'
class Sheep
# ...
end
sheep = Sheep.new
sheep_queue = Queue.new
sheep_queue << sheep
5.times.map do
Thread.new do
begin
sheep = sheep_queue.pop(true)
sheep.shear!
rescue ThreadError
# raised by Queue#pop in the threads
# that don't pop the sheep
end
end
end.each(&:join)I left out the Sheep implementation because it's the same. Now, instead of each thread sharing the sheep object and racing to shear it, the Queue provides the synchronization.
If you run this against MRI, or any of the other truly parallel Ruby implementations, it will produce the expected result every time. We've eliminated the race condition in this code. Even though all the threads may call the Queue#pop method at more-or-less the same time, it uses a Mutex internally to ensure that only one thread can receive the sheep.
Once this single thread receives the sheep, the race condition disappears. With just one thread, there's no one else to race with!
The reason I suggest using Queue instead of a lock is that its simpler to use a Queue correctly. Locks are notoriously easy to get wrong. They bring new concerns like deadlocking and performance degradations when used incorrectly. Using a data structure is like depending on an abstraction. It wraps up the tricky stuff in a more restrictive, but simpler API.
Lazy initialization
I'll just quickly point out that lazy initialization is another form of the the check-then-set race condition. The ||= operator effectively expands to
@logger ||= Logger.new
# expands to
if @logger == nil
@logger = Logger.new
end
@loggerLook at the expanded version and imagine where the interleavings could occur. With multiple threads and no synchronization, it's definitely possible for that @logger to be initialized twice. Again, initializing a Logger twice may not be a problem in this case, but I have seen bugs like this in the wild that do cause issues.
Reflections
I want to leave you with some lessons at the end of all this.
4 out of 5 dentists agree that multi-threaded programming is hard to get right.
At the end of the day, all that the GIL guarantees is that MRI's native C implementations of Ruby methods will be executed atomically (but even this has caveats). This behaviour can sometimes help us as Ruby developers, but the GIL is really there for the protection of MRI internals, not as a dependable API for Ruby developers.
So the GIL doesn't 'solve' thread-safety issues. As I said, getting multi-threaded programming right is hard, but we solve hard problems every day. One way that we work with hard problems is with good abstractions.
For example, when I need to do an HTTP request in my code, I need to use a socket. But I don't usually use a socket directly, that would be cumbersome and error-prone. Instead, I use an abstraction. An HTTP client provides a more restrictive, simpler API that hides the socket interactions and associated edge cases from me.
If multi-threaded programming is hard to get right, maybe you shouldn't be doing it directly.
"If you add a thread to your application, you've probably added five new bugs in doing so."
We're seeing more and more abstractions around threads. An approach that's catching on in the Ruby community is the Actor model of concurrency, with the most popular implementation being Celluloid. Celluloid provides a great abstraction that marries concurrency primitives to Ruby's object model. Celluloid can't guarantee that your code will be thread-safe or free from race conditions, but it wraps up best practices. I encourage you give Celluloid a try.
These problems that we're talking about aren't specific to Ruby or MRI. This is the reality of programming in a multi-core world. The number of cores on our devices is only going up, and MRI is still figuring out its answer to this situation. Despite its guarantees, the GIL's restriction on parallel execution seems like the wrong direction. This is part of MRI's growing pains. Other implementations, like JRuby and Rubinius, are running truly parallel with no GIL.
We're seeing lots of new languages that have concurrency abstractions built-in at the core of the language. The Ruby language doesn't have any of this, at least not yet. Another benefit of relying on abstraction is that the abstractions can improve their implementation, while your code remains unchanged. For example, if the implementation of Queue switched from relying on locks to using lock-free synchronization, your code would reap the benefits without any modification.
For the time being, Ruby developers should educate themselves about these issues! Learn about concurrency. Be aware of race conditions. Thinking about code as interleavings can help you reason about race conditions.
I'll leave off with a quote that's influencing much of the work being done in the larger field of concurrency today:
Don't communicate by sharing state; share state by communicating.
Using data structures for synchronization supports this; the Actor model supports this. This idea is at the core of the concurrency model of languages like Go, Erlang, and others.
Ruby needs to look to what's working in other languages and embrace it. As a Ruby developer, you can do this today by trying out and supporting some of these alternative approaches. With more people on board, these approaches could become the new standard for Ruby.
Thanks to Brian Shirai for reviewing a draft of this.
Comments
Bob ·
Nice article. In your reflections, I think your quip should have said: "5 out of 4 dentists agree that multi-threaded programming is hard to get right."
Soleone ·
Anazing read, thanks for putting that together! Looking forward to possibly more guest posts? :)
Alexandr ·
Hello, Jesse!
5.times.map do
Thread.new do
begin
new_sheep = sheep_queue.pop(true)
unless sheep.shorn?
sheep.shear!
end
rescue ThreadError
# raised by Queue#pop in the threads
# that don't pop the sheep
end
end
end.each(&:join)
is not a rewrite of a Mutex version unless sheep.shorn? which would look like
mutex = Mutex.new
5.times.map do
Thread.new do
mutex.synchronize do
unless sheep.shorn?
sheep.shear!
end
end
end
end.each(&:join)
, but a version without any sheep.shorn? checking like that
mutex = Mutex.new
5.times.map do
Thread.new do
mutex.synchronize do
begin
sheep.shear!
sheep = nil
rescue
end
end
end
end.each(&:join)
Alex ·
Hello!
Like this article about GIL. What you mean by "this would work without GIL on Java"? What I need to do?
Jesse Storimer ·
Alex: not sure what you're referring to, can you give more context?
Soleone: Thanks! More coming soon :)
Brian ·
I think what Alex is trying to say is that checking
sheep.shorn?is not needed, sincesheep_queue.pop(true)will raiseThreadErrorif the queue is empty. TheQueuehas eliminated the chance of the sheep being sheared twice.So the example could be:
Thread.new do
begin
sheep_queue.pop(true).shear!
rescue ThreadError
end
end
Or even:
Thread.new do
sheep = sheep_queue.pop(true) rescue nil
sheep.shear! if sheep
end
Unless
Sheep#shear!could raiseBrokenShearsError:)Ruby Inside: These comments really need a preview button. (hope I got it right)
Jessie: I've really enjoyed your work. Keep it up!
Jesse Storimer ·
Brian, Alex: I understand what you're saying now. You're exactly right. The data structure ensures that only one thread will shear the sheep, so the conditional is unnecessary. I updated the code example accordingly.