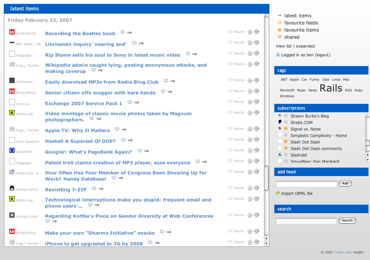
Ben Smith has just relaunched his Rails-powered online feed reader, Trawlr, after rewriting it using Rails 1.2. It's significantly slicker than before, and includes a screencast to get you up to speed quickly.
I caught up with Ben and asked him a few questions about Trawlr's redevelopment and new focus, along with how Trawlr is deployed and his plans for the future.
Ruby Inside: Trawlr's interface is very clean and easy to use. It also seems quite unique and simple in an area where readers often use similar interfaces. What have been the inspirations behind Trawlr's design?
Ben Smith: When I started work on trawlr I was aiming to get real-world experience developing my first Rails application and like most programmers I had a specific itch to scratch. I originally started using RSS through Mozilla Thunderbird but found it difficult to keep my feed subscriptions synced between work and home PCs (and knowing what I'd already read). When I was looking for an online RSS reader I didn't find any that I felt comfortable using; my main problem was that I wanted a "river of news" style view, where items from all feeds are combined and mashed together. Almost all the readers I looked at kept each feed separate and behaved like email where you had to keep marking items or feeds as read to prevent a huge, overwhelming backlog.
The way I use RSS is to subscribe to a large number of feeds (over 300) and then simply 'dip in' and read when I have time. With trawlr you can tag feeds and also mark them as 'favourite'. I use this feature to highlight feeds that I want to keep on top of (and use that as my 'home' view). I think trawlr has evolved since its first design towards being a great 'personal' news aggregator... you subscribe to as many feeds as you have an interest in and then filter down depending on context (for me it's .NET at work and Rails at home)!
I'd also readily admit that the latest UI has been influenced by Google Reader, but with a slightly cleaner look. The RSS reader has been optimised for quickly scanning through lots of feeds, the favicon from each site is used where available to help recognise feeds.
You've told me that the new version of Trawlr has been heavily reworked to use the RESTful features of Rails 1.2. What have been your most notable experiences with migrating over to using REST techniques? How has it improved your development process?
When I first discovered the REST features in Rails (via DHH's "World of Resources" presentation) I didn't really get it. Once I started to understand that REST is all about modeling 'things' and their relationships by creating rich associations it started to make sense.
The additional benefit of using the same code to respond according to the requesting user agent is a major bonus. Within trawlr I mainly use the REST features to keep the code DRY for different response types; rss and opml being two current examples. In the future I hope to add a mobile version.
Are you, or will you be, using RESTful features to provide an API for Trawlr users? If so, how will that be rolled out?
Currently I haven't specifically implemented an API but that is definitely something for the future. Thanks to Rails' REST features there isn't much extra code required, instead documentation becomes key. I can definitely see a future API that can then be used to build an alternate interface on top of or create interesting mash-ups (it would be a great candidate for ActiveResource). There is potential here for using the API to create an offline reader; one of the weak points of online aggregators.
How is Trawlr deployed and what sort of systems does it run on?
Trawlr runs on a Slicehost VPS using Ubuntu Linux with NginX proxying to a mongrel cluster. That's a really lightweight deployment option and very easy to get up and running. Capistrano is used for deployment which allows a lightening fast turnaround time from development, testing to live.
Have you designed Trawlr in a way that it could deal with significant loads? What's your strategy for scaling Trawlr if it becomes necessary?
For scalability I'm following the Getting Real approach and will worry about that when the problem arises! Thanks to Rails' share-nothing architecture and the current setup (using a VPS) increasing performance can be done relatively simply (deprec can get a new Ubuntu box up ready to serve in a matter of minutes). The application code has been tuned using the Query Analyzer plugin (MySQL) with relevant database indexes and some of the heavy SQL has been tuned by hand for the most expensive queries. The main RSS reader also makes heavy use of AJAX to keep the UI responsive and allow minimal network transfer (along with gzip compression on relevant output by NginX). On deployment all the CSS and JavaScript files are compressed / minified using the fantastic AssetPackager plugin.
You have said that some of your future plans for Trawlr will include community participation and collaboration. Could you elaborate? How could Ruby Inside readers, for example, help you out?
Ruby Inside's readers can help in a good number of ways, you could start by checking out the site - all constructive feedback is much appreciated and you can help shape the future of the site.
The next stage of development is towards the community aspect and collaboration. At the moment you can comment on any feed item, mark it as a favourite or share it (which makes it available on your public shared page). Each of these is valuable feedback and I want to use this in a 'digg style' voting system. Along with the the number of views, an individual item's popularity can be used to promote it to a "best of the web". Casual RSS users could then simply subscribe to these 'super' feeds (filtering by relevant tags). The possibilities of finding useful content become huge.
Another future development is lifestreaming. You currently get a shared items public page (example). In future you should also have a lifestream page which combines all the feeds about you (twittter, flicker, del.icio.us, last.fm)... completely optional of course!
Finally, there are some interesting opportunities with using your subscriptions to discover new feeds. For example, I subscribe to a number of Rails blogs, other users might have a similar list plus a few extra feeds I haven't yet found. It's a similar idea to last.fm where your listening habits can be used to suggest new interesting bands.